
Jupyter Notebooks in Jekyll
Converting Jupyter notebooks to jekyll posts
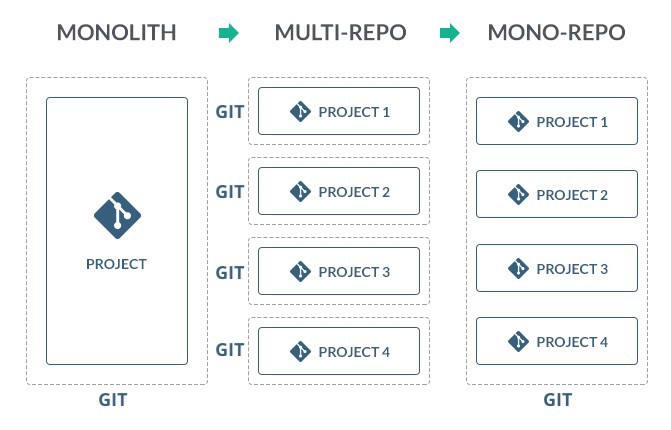
Monorepos have become more of a norm these days due to large software with many components and micro services, most languages have tools for working with mono repos such as pants on python or yay on the web development side, monorepos make it easier to manage software with many components or a collection of software solutions at one place.
An example of using monorepos is grouping a set of machine learning APIs under the same repository to simplify deployment, and general code maintenance. the code is organized as below:
root
├── audio
│ ├── classification
│ │ └── src
│ ...
├── image
│ ├── classification
│ │ └── src
│ ...
├── text
│ ├── classification
...
Inside each API folder is a set of files required to build and run the API as a lambda function, it has this following structure:
├── Dockerfile
├── README.md
├── requirements.txt
├── src
We want to build and deploy each of these APIs individually, the general process would be to create a github actions workflow for each API, that will lead to creating 10+ workflow files which is not ideal, we could automate the process of generating these files but where is the fun that? in order to make the workflow simpler, we have to handle finding what function directory to build externally and only let the github action workflow setup and run that script.
I chose to write this script in python to try the library
typer, its a cli application framework that
abstracts the process of creating cli application in a similar way to fastAPI,
typer adds a lot of useful information to a cli app such as --help for each
command and the overall CLI application.
The build process for each of the APIs is a standard docker build, tag and push with the addition of updating a lambda function with the newly pushed image. let’s first create the typer app.
from typer import Typer
app = Typer(name="Workflow runner", no_args_is_help=True)
Now we can perform the build steps in a function using the os module to directly call build commands with appropriate parameters.
def run_workflow(
code_path: str,
ecr_repository: str,
lambda_function_name: str,
account_id: str = "000",
ecr_tag: str = "latest",
ecr_region: str = "us-east-2",
) -> None:
# login to ECR
ecr_registery = f"{account_id}.dkr.ecr.{ecr_region}.amazonaws.com"
os.system(
f"aws ecr get-login-password | docker login --username AWS --password-stdin {ecr_registery}"
)
# Build and tag image
os.system(f"docker build -t {ecr_registery}/{ecr_repository}:{ecr_tag} {code_path}")
# push image to ECR
os.system(f"docker push {ecr_registery}/{ecr_repository}:{ecr_tag}")
# update the lambda function with the new image
os.system(
f"aws lambda update-function-code --function-name {lambda_function_name} --image {ecr_registery}/{ecr_repository}:{ecr_tag}"
)
The script can now perform the full build process given appropriate arguments, since the script is going to be used in a pipeline, these argument have to come from somewhere, if we look at the function arguments, only the first 3 need to be changed constantly, the rest can be fixed, let’s try to find the values of each of the first 3 function parameters.
This is the path to the code where there is a dockerfile that builds the image,
to determine which API folder was modified and should be rebuilt and updated, we
can check the list of changed files in the last commit compared to HEAD then
check if the file name starts with one of the APIs root directory or
alternatively, we can find the parent of the changed file where there is a
dockerfile, I went with fixing the directories inside the script to make things
simpler. we can use git to get the names of files that have changed between the
last 2 commits
git diff --name-only HEAD HEAD~1
This is the ECR registery where the image will be pushed to. this can be manually constructed from the account ID, region and repository name as follows:
ecr_registery = f"{account_id}.dkr.ecr.{ecr_region}.amazonaws.com"
This is the URl to the ECR repository where the created image should be uploaded, each API will have its own repository, we can directly fix this in the code since it does not change.
The name of the lambda function to update with the new image, to make things simpler, we will use the same name for the lambda function as the ECR repository.
Now that we know how to obtain the values of the first 3 arguments, we can write the function as follows.
def get_changed_path_repo() -> Generator[Tuple[str, str], None, None]:
"""
Returns path that was modified by last commit and ECR repository name.
"""
# mapping of paths to ECR repositories
path_repository_map = {
# image APIs
"image/classification": "website-apis-image-classification",
# text APIs
"text/classification": "website-apis-text-classification",
# audio APIs
"text/classification": "website-apis-text-classification",
}
os.system("git diff --name-only HEAD HEAD~1 > /tmp/modified_path.txt")
with open("/tmp/modified_path.txt", "r") as f:
modified_paths = f.read()
modified_paths = modified_paths.split("\n")
modified_paths = [path for path in modified_paths if path] # remove empty lines
modified = {}
for path, repo in path_repository_map.items():
for modified_path in modified_paths:
if modified_path.startswith(path):
modified[path] = repo
return modified.items()
With this we have essentially automated the entire build process for all of the 10+ APIs, to make the script more versatile, we can add a command for manual runs and another that finds what’s changed and builds it accordingly.
@app.command(name="run", help="run workflow with given options.")
def run_manual(
code_path: str,
ecr_repository: str,
lambda_function_name: str,
account_id: str = "0000",
ecr_tag: str = "latest",
ecr_region: str = "us-east-2",
) -> None:
"""wrapper to run workflow with given options."""
run_workflow(
code_path,
ecr_repository,
lambda_function_name,
account_id,
ecr_tag,
ecr_region,
)
@app.command(name="run-auto", help="run workflow with automatically detected changes.")
def run_auto() -> None:
"""
Run workflow with automatically detected changes.
"""
for path, repo in get_changed_path_repo():
run_workflow(path, repo, repo) # ecr repo same as lambda function name
now to run the typer application we need these 2 lines of code.
if __name__ == "__main__":
app()
Finally we can setup the github workflow, the only used actions are aws login and python, we also need to fetch the last 2 commits from the repository history, by default the checkout action only fetches the last commit, we can instruct it to fetch the last 2 commits with a simple flag in the workflow file.
name: Auto Build Updated API
on:
push:
branches: [master]
paths-ignore:
- "*/**/README.md"
workflow_dispatch:
jobs:
build:
name: Build Image
runs-on: ubuntu-latest
steps:
- name: Check out code
uses: actions/checkout@v3
with:
fetch-depth: 2 # fetch last 2 commits
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: $
aws-secret-access-key: $
aws-region: us-east-2
- name: Login to Amazon ECR
uses: aws-actions/amazon-ecr-login@v1
- name: Setup Python
uses: actions/setup-python@v4
with:
python-version: "3.9"
- name: Automated changes detection and build
run: |
python -m pip install --upgrade typer
python runner run-auto
now we have everything we need, this workflow will run the script on every
commit, check if there are files updated inside the APIs that are not
README.md then rebuild the docker image, push it to ECR and finally update the
lambda function with the new image. let’s checkout what functionality does typer
add to our CLI application
$ python runner
Usage: runner [OPTIONS] COMMAND [ARGS]...
Options:
--install-completion [bash|zsh|fish|powershell|pwsh]
Install completion for the specified shell.
--show-completion [bash|zsh|fish|powershell|pwsh]
Show completion for the specified shell, to
copy it or customize the installation.
--help Show this message and exit.
Commands:
run run workflow with given options.
run-auto run workflow with automatically detected changes.
In addition to our specified commands typer also generates auto-completion for
various shells with the option to install them directly, this can be very
helpful in large application with many functionality, typer also generates a
–help flag for each command.
$ python runner run –-help
Usage: runner run [OPTIONS] CODE_PATH ECR_REPOSITORY LAMBDA_FUNCTION_NAME
run workflow with given options.
Arguments:
CODE_PATH [required]
ECR_REPOSITORY [required]
LAMBDA_FUNCTION_NAME [required]
Options:
--account-id TEXT [default: 00000]
--ecr-tag TEXT [default: latest]
--ecr-region TEXT [default: us-east-2]
--help Show this message and exit.
Converting Jupyter notebooks to jekyll posts

Automating the Boring stuff with python
how to minimal note taking setup
giving your text editor super powers