Zero Setup SQL Migration in production
November 23, 2024
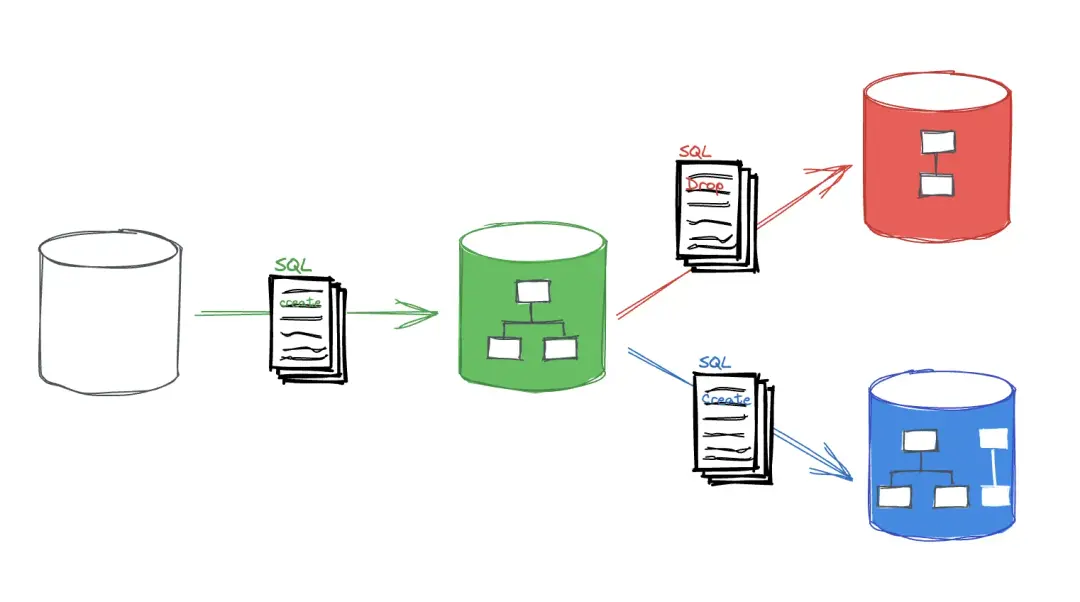
Database migrations are a crucial part of application development, especially
when dealing with dynamically generated tables. Traditional migration tools
often require extensive setup and can be cumbersome for tables that are created
on the fly. I ran through this problem when we added a new feature that
generates text using an LLM, and we needed to store the generation price as part
of the metrics, traditionally, this would require creating migrations and
running them, but I wanted to avoid that, because this table is generated on the
fly and I didn’t want to maintain a migration history for it, so I wrote
SQLMigrately, a simple python library that allows you to migrate tables without
any setup.
The Problem
When working with analytics or monitoring systems, tables are often generated
based on runtime metrics. These tables might not exist when deploying updates,
making traditional migration tools less effective.
A Simple Solution
Instead of relying on migration frameworks, we can use a more direct approach
where the table structure is defined in code. This way, we can dynamically
update tables without maintaining migration history.
SQLMigrately
SQLMigrately is a simple tool that performs SQL migrations live at runtime. It
is designed to be used in development environments, where you want to apply
changes to your database schema without having to stop the application or in
production if you are brave enough and know what you are doing (me).
Installation
Usage
The main function of the library is migrate_table, which given a dataframe, a
table name, and a database engine, will update the table schema to match the
dataframe schema. the function has other optional parameters that allow you to
control the behavior of the migration.
import pandas as pd
from sqlmigrately import migrate_table
from sqlalchemy import create_engine
# create a connection to the database
engine = create_engine('sqlite:///test.db')
# read the current schema
df = pd.read_sql('SELECT * FROM users', engine)
df
| name |
age |
city |
| John |
20 |
New York |
| Doe |
30 |
Los Angeles |
# create a dataframe with the new schema
df = pd.DataFrame({
'name': ['Jane', 'Smith'],
'age': [23, 42],
'city': ['Ohio', 'California'],
'country': ['USA', 'USA']
})
# apply the migration
migrate_table(df, 'users', engine, push_data=True)
# show updated table and schema
df = pd.read_sql('SELECT * FROM users', engine)
| name |
age |
city |
country |
| John |
20 |
New York |
NULL |
| Doe |
30 |
Los Angeles |
NULL |
| Jane |
23 |
Ohio |
USA |
| Smith |
42 |
California |
USA |
Function Parameters
the full signature of the migrate_table function is as follows:
def migrate_table(
table_name: str,
df: pd.DataFrame,
db_eng: Engine,
*,
push_data: bool = True,
add_cols: bool = True,
remove_cols: bool = False,
column_type_map: dict = None,
):
"""
Update given `table_name` schema in the database to match the schema of the given `df`.
Assumes minimal changes to the table schema.
Args:
table_name (str): name of the table
df (pd.DataFrame): dataframe to migrate
db_eng (Engine): sqlalchemy engine
push_data (bool, optional): whether to push dataframe data to the table. Defaults to True.
add_cols (bool, optional): whether to add new columns in dataframe to the table. Defaults to True.
remove_cols (bool, optional): whether to remove removed columns from the table. Defaults to False.
column_type_map (dict, optional): mapping of column names to their types. Defaults to None, which means that the types are inferred from the dataframe.
Raises:
TableDoesNotExistError: raised when the given table does not exist in the database
"""
The library also provides other helper functions that can be useful for dealing
with SQL databases, such as:
get_schema_diff: get the difference between the dataframe and the table
schema
@dataclass
class ColumnDiff:
"""class to hold the difference between two sets of columns"""
added: List[Dict[str, Any]] = field(default_factory=list)
removed: List[Dict[str, Any]] = field(default_factory=list)
def get_schema_diff(table_name: str, df: pd.DataFrame, db_eng: Engine) -> ColumnDiff:
"""get the difference between the dataframe and the table schema"""
get_table_schema: get the schema of a table in the database
def get_table_schema(table_name: str, db_eng: Engine) -> Dict[str, str]:
"""get mapping of table columns and their types"""
map_type: map pandas types to sql types
def map_type(dtype: str, *, default: str = "TEXT") -> str:
"""map pandas dtype to sqlalchemy type"""



